
[Trimming] MetaCLIP2
Collection
Collection of trimmed Meta's MetaCLIP2 models. The models are sorted alphabetically. • 1164 items • Updated
This model is a 77.31% smaller version of facebook/metaclip-2-worldwide-b16-384 optimized for Kyrgyz language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
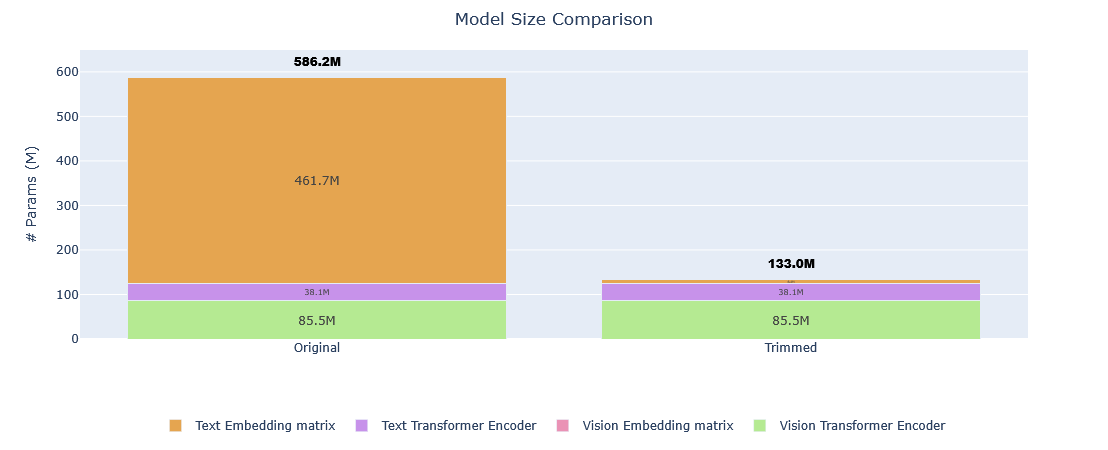
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 901,629 tokens | 16,384 tokens | 98.18% |
| Model size | 586,249,729 params | 133,004,289 params | 77.31% |
from transformers import pipeline
# load pipeline
image_classifier = pipeline(model="alphaedge-ai/metaclip-2-worldwide-b16-384-kir-16384", task="zero-shot-image-classification")
# load image and candidate labels
image = "http://images.cocodataset.org/val2017/000000039769.jpg"
candidate_labels = ["Potential label 1 in Kyrgyz", "Potential label 2 in Kyrgyz", "Potential label 3 in Kyrgyz", "Potential label 4 in Kyrgyz"]
# run inference
outputs = image_classifier(image, candidate_labels)
print(outputs)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("alphaedge-ai/metaclip-2-worldwide-b16-384-kir-16384")
images = [
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg",
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
"https://huggingface.co/datasets/huggingface/cats-image/resolve/main/cats_image.jpeg"
]
texts = ["Text 1 in Kyrgyz", "Text 2 in Kyrgyz", "Text 3 in Kyrgyz", "Text 4 in Kyrgyz"]
image_embeddings = model.encode(images)
text_embeddings = model.encode(texts)
print(image_embeddings.shape, text_embeddings.shape)
similarities = model.similarity(image_embeddings, text_embeddings)
print(similarities)
@misc{chuang2025metaclip2worldwide,
title={Meta CLIP 2: A Worldwide Scaling Recipe},
author={Yung-Sung Chuang and Yang Li and Dong Wang and Ching-Feng Yeh and Kehan Lyu and Ramya Raghavendra and James Glass and Lifei Huang and Jason Weston and Luke Zettlemoyer and Xinlei Chen and Zhuang Liu and Saining Xie and Wen-tau Yih and Shang-Wen Li and Hu Xu},
year={2025},
eprint={2507.22062},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.22062},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
facebook/metaclip-2-worldwide-b16-384